
Introduction
Today, you will observe visuals crafted by algorithms like Stable Diffusion. However, putting together videos with AI is a much more difficult process. As someone who works with a media production company, it is confidently stated that creativity generated by AI has yet to reach the level of quality needed for mainstream use of diffusion video generation.
There is a mile of difference between AI-generated videos and industry standards. Stable Diffusion is not just limited to producing static images; it has the potential to create visually impressive AI videos with the help of certain tools and extensions. Here's an easy guide to creating frames for an animated GIF or a video with Stable Diffusion.

In this article
Can Stable Diffusion Generate Video?
Yes, it is possible to make videos or GIFs with Stable Diffusion. The latest img2img features can craft short videos or GIFs that resemble videos. Moreover, AI technology can quickly provide animated frames for the video.
Additionally, specialized tools are available for creating videos using the Stable Diffusion platform. These tools can be used to generate MP4 videos with the help of the Web UI.
Is Stable Diffusion Good?
A stable diffusion video generation is an exceptional tool for producing gorgeous, realistic pictures. Although its utilization might be associated with drawbacks, the advantages exceed any negative impacts. Because of its convenience, versatility, and astonishing results, Stable Diffusion is essential for anyone fond of attractive visuals.
Stable Diffusion is a great resource for those looking to broaden their artistic capabilities. It can help you to find inspiration for new projects or to explore different visual styles and techniques.
Its user-friendly interface lets you customize the images you create to fit your specifications.
And you don't have to be an experienced artist to take advantage of its capabilities - it's easy to use regardless of your skill level. With Stable Diffusion, you can use your creativity to produce stunning images and designs you will proudly show off.
How Does Stable Diffusion Work?
The core concept of image generation via diffusion models is based on the fact that advanced computer vision models can be trained with sufficient data. Stable Diffusion offers a powerful approach to this problem, using an algorithm to generate an image based on specific parameters.
The algorithm of stable diffusion generate video initiates the process with a random noise image continually refined using a special diffusion technique. The result is a visually appealing, high-resolution creation that looks like a skilled artist made it. Here is the process:
1. Departure To Latent Space:
The process begins by training an autoencoder to encode the images into lower-dimensional latent representations. It can then utilize the trained encoder, E, to convert the original images into smaller, compressed versions. The trained decoder, D, can reconstruct the original image from the latent data.
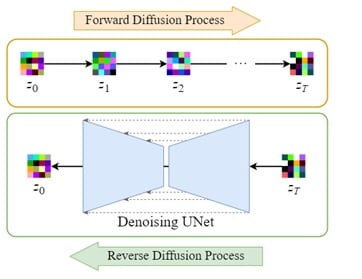
2. Latent Diffusion:
The forward diffusion process involves adding noise to the encoded latent data, while the reverse diffusion process entails eliminating this noise from the same data. It ensures that the images can be transformed back to their original form.
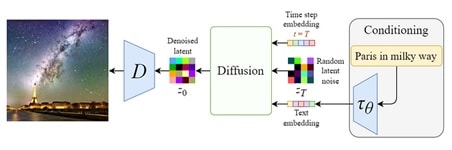
3. Conditioning:
The Stable diffusion video generation Model leverages the ability to generate images from textual prompts by augmenting the denoising U-Net with a cross-attention mechanism.
It is done by providing the inner model with conditioning inputs, such as text embeddings generated by a language model like BERT or CLIP, and other spatial inputs like images or maps. Depending on the type of conditioning input, it is either mapped into the U-Net through the Attention layer or added through concatenation.
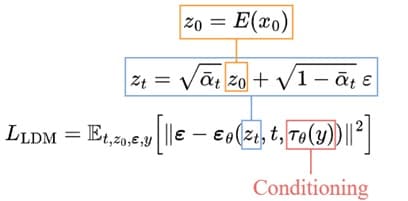
4. Training And Sampling:
The training goal is similar to the basic diffusion model, with a few alterations: taking in latent data zₜ rather than the image xₜ, the U-Net also includes a conditioning input 𝜏θ(y). The denoising procedure will be much quicker because the latent data is much smaller than the initial photo.
How To Make A Video With Stable Diffusion?
Deforum Stable Diffusion is a specialized version designed to create video clips and transitions using Stable Diffusion-generated images. People of any skill level or expertise can use this open-source, community-driven software tool.
Developers are always willing to accept new contributions if you're interested in participating in the project. The Deforum stable diffusion video generation pipeline allows you to make complete simulations without using your GPU.
• Generate A Video Using Deforum
To copy Deforum stable diffusion generate video v0.5 to your Google Drive, click the "Copy to Drive" button. Once you do, you will be sent a new copy of the Colab notebook on your own Google Drive and can then close the original one, as you won't need it anymore.
• Step 1: Install The Deforum Extension
Currently, you can take full advantage of Google Colab and connect it to an external GPU. Be aware that you are given some complimentary credits for Google Colab; however, if you exhaust them, you must either purchase more or wait a few days for them to be restored.
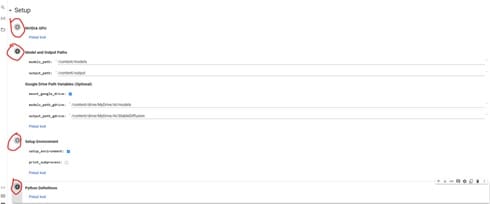
• Step 2: Write Your Prompts
Using stable diffusion video generation models (or any other LLM) for engineering or developing our communication techniques is increasingly important today.
It is recommended to provide detailed and specific prompts when generating images to achieve the desired effects. It is also important to provide a preview of any desired animation settings or effects, such as lighting, time of day, and art style or cultural references.
Avoiding titles of works or dropping artists' names is important, but for some projects, it can produce interesting results. When generating an animation, always provide the first prompt and any additional prompts before beginning.
Test out the prompts first, then use the ones that work best in the final animation. With the appropriate techniques, creators can achieve the desired effects for a successful animation.
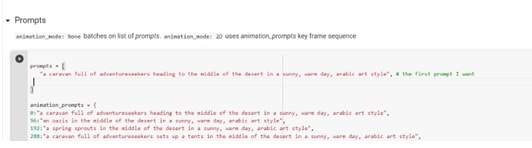
• Step 3: Adjust Deforum Settings
It is suggested to use the override_with_file option in stable diffusion generate video, so your settings are always saved and can be reused, shared, or reverted to. For 9:16 images, try 448 x 706; for vertical, 706 x 448; for square, 512 x 512.
In the sampling settings, enter a number in the seed line if you like a certain image or -1 for random. For the step value, a range between 50 and 60 is suggested. Finally, the scale value can be set between 7 and 12.
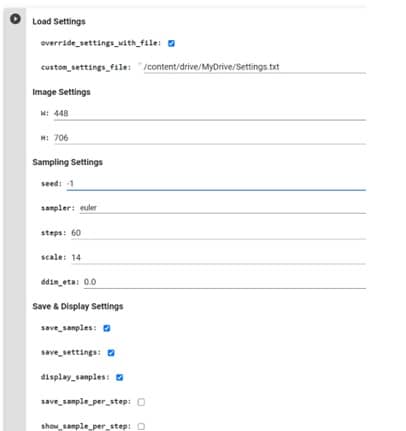
• Step 4: Generate Your Video
The final step after generating videos is to download the images and input them into a suitable video editing program before rendering the video. One free software for this is DaVinci Resolve 18, which offers a range of features to give you more control over the final product.
Alternatively, the "create video from frames" code can be used, but this may not always yield the desired result.
How To Write Stable Diffusion Prompts
If you have used any AI image generation tools such as Stable Diffusion, DALL-E, or MidJourney, you will understand how essential the correct wording is when putting forward a prompt. A precise and thorough prompt can turn any idea into a stunning image, while a vague phrase can result in a bizarre, unsettling image. Here are some of the tips:
1. Be Specific: Stable diffusion video generation thrives when provided with concrete instructions, compared to MidJourney, which is more open-ended. To generate landscapes with Stable Diffusion, you should be detailed in your instructions, using words that accurately describe the image you are looking for.
Experiment with different phrases and see what type of results they yield. It's beneficial to observe how a change of a few keywords may drastically change the picture and incorporate them into the prompt to achieve the desired outcome.
2. Be Sure About The Art Style And Creativity: In addition to indicating the content of your desired image, you should also specify the style you'd like. For example, if you're seeking an acrylic painting-like appearance, your prompt should read something like "name, acrylic painting" or "name, acrylic-style."
This formula offers the best chance of getting close to the style you're looking for. Stable diffusion has various looks and styles - pencil drawings, clay models, and even 3d renderings with Unreal Engine.
3. Include The Artist's Name For More Clarity: A stable Diffusion is a great option if you're looking to evoke a specific artist's style within a work. It's a powerful tool that can truly capture the essence of a particular artist if you provide it with the right prompt.
You can even combine different artists, producing a unique fusion of the two artists' styles. This artistic experimentation can yield exciting and unexpected results, so don't be afraid to try diffusion video generation.
4. Analyze Your Keywords: If you need to emphasize a certain keyword more in the prompt, Stable Diffusion provides weighting options. This feature permits you to assign greater significance to some words over others for more precise results. It is especially useful when the output is almost correct but could benefit from more focused attention on a specific term.
5. Other References: Recently, there has been a huge surge in the amount of AI art available online. Everyone is producing these kinds of pieces, and many of these creations include the keywords or formulas used to generate them. It indicates multiple user-generated images across the web, easily amounting to millions.
Additional Technical Settings For Generating Prompts:
Creating an effective prompt is the most difficult part of using Stable Diffusion; however, adjusting other settings can considerably impact the outcome.
- CFG: This parameter sets the level of confidence the Stable Diffusion AI has in generating a response that accurately reflects your prompt. Increasing the value will make the AI generate more faithful prompts while lowering the value will give the AI more leeway to exercise autonomy in the text generated. Test out different values to see the range of outputs you get.
- Sampling Approach: The image is cleaned up from the interference and transformed into identifiable patterns using a variety of algorithms, such as Euler_a, k_LMS, and PLMS, which are widely used for stable diffusion video generation.
- Sampling Stages: The number of iterations to reach an image's final version may vary. Generally, fewer steps yield satisfactory outcomes, while higher numbers may not lead to any additional improvement. It is often recommended to begin with a relatively low number of steps, gradually increasing if needed. Going beyond 150 iterations typically does not result in any further improvement.
Conclusion
Creating a real-time video with stable diffusion video generation could be quite laborious and time-consuming. As technology advances, however, it is expected to eventually become simpler to create videos with Stable Diffusion as it is now to generate pictures. However, until such advancement is achieved, users must avail themselves of various sub-tools and commands that might not be understandable for all users.
FAQ
-
Can you animate with Stable Diffusion?
Creating animations can be done in several ways. Stability AI enables users to use its Stable Diffusion models, such as Stable Diffusion 2.0 and Stable Diffusion XL, for animation creation. Additionally, users can use the animation endpoint to access the pre-made templates, thus allowing them to create animations quickly and in larger quantities. -
What can Stable Diffusion generate?
Stable Diffusion is an AI image generator that can be customized to your liking. It has an open-source platform that allows you to create your datasets and tune the generated images. Furthermore, you can train your models to create images that fit your preferences. -
Is Stable Diffusion only for images?
Stable Diffusion is a method that enables the creation of images from text descriptions. It is a superior choice compared to mid-journey and DALLE-2, as it can precisely translate the text into visuals. It is achieved through sophisticated algorithms and a convolutional neural network, which converts the written content into a corresponding image.
